Designer Diary: The Search for AlphaMystica
By Tysen Streib
Spoiler alert: This doesn’t have a happy ending. Digidiced has been hard at work for more than a year trying to produce a Hard version of its AI for Terra Mystica using machine learning. Our results have been a lot less impressive than we were hoping for. This article will describe a little bit about what we’ve tried and why it hasn’t worked for us.
If you’ve paid attention to the latest developments in AI, you’ve probably heard of AlphaGo and AlphaZero, developed by Google’s DeepMind. In 2017, AlphaGo defeated Ke Jie, the #1 ranked Go player in the world. AlphaGo was developed by using a massive neural network and feeding it hundreds of thousands of pr ofessional games. From those games, it learned to predict what it thought a professional would play. AlphaGo then went on to play millions of games against itself, gradually improving its evaluation function little by little until it became a superhuman monster, better than any human player. The defeat of a human professional was thought to be decades away for a game as complex as Go. But AlphaGo shocked everyone with its quantum leap in playing strength. AlphaGo was able to come up with new strategies, some of which were described as “god-like.”
ofessional games. From those games, it learned to predict what it thought a professional would play. AlphaGo then went on to play millions of games against itself, gradually improving its evaluation function little by little until it became a superhuman monster, better than any human player. The defeat of a human professional was thought to be decades away for a game as complex as Go. But AlphaGo shocked everyone with its quantum leap in playing strength. AlphaGo was able to come up with new strategies, some of which were described as “god-like.”
But it didn’t stop there. In December of 2017, DeepMind introduced AlphaZero – a method that also learned the game of Go, but this time didn’t use any human played games. It learned entirely from self-play being only told the rules of the game. It was not given any suggestions or strategies on how to play. AlphaZero not only able to learn from self-play alone, it was able to get stronger than the original AlphaGo. And on top of that, the same methodologies were used for Chess and Shogi and the DeepMind team showed results that AlphaZero was able to solidly beat the top existing AI players in both of these games (which were already better than humans). Since these results have come out, there has been some criticism around if the testing conditions were really fair to the existing AI programs, so there is a little debate as to whether AlphaZero is actually stronger, but it is an outstanding achievement nonetheless.
It also became quite clear that AlphaZero approached chess differently than Stockfish (the existing AI they competed against). While Stockfish examined 70 million positions per second, AlphaZero only examined 80,000. But AlphaZero was able to pack a lot more positional and strategic evaluation into each of those positions. By examining the games that AlphaZero played against Stockfish it became obvious to a lot of people that AlphaZero was much better at positioning its pieces and relied less on having a material advantage. In many cases AlphaZero would sacrifice material in order to get a better position, which it later used to come back and secure a win. It suggested the possibility that there might be a resurgence in chess programming ideas, which had been stagnating in recent years.
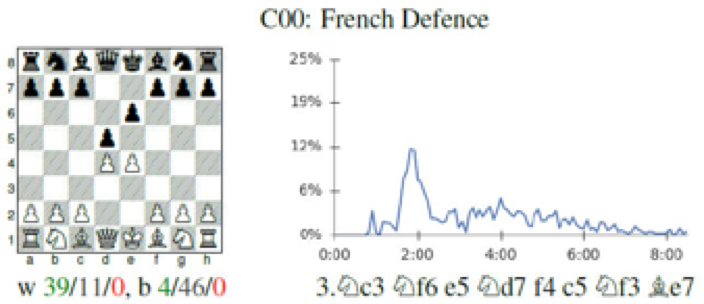
The DeepMind team was able to show that AlphaZero learned many human-discovered opening moves. They showed several examples of how different openings gained and lost popularity as it continued to learn.
As Digidiced’s AI developer, these were exciting developments for me. I’ve had experience with machine learning and neural networks before and have been playing around with them for many years. I once developed a network as a private commission for a professional poker player that could play triple draw low at a professional level. I began to wonder if I could use some of these same techniques for Digidiced’s Terra Mystica app. One of the compelling features of AlphaGo was that it was largely based on something called a convolutional neural network (CNN). A CNN is also used in other deep learning applications like image recognition and is good at identifying positional relationships between objects. AlphaGo was able to use this structure to identify patterns on the Go board and determine the complex relationships that could be formed from the different permutations of stones.
While Terra Mystica takes place on a hex-based map instead of a square grid, a CNN can still be applied to it so that the proximity of players’ buildings can be incorporated, which is a critical part of TM strategy. However, there are several things that make TM a much more complicated game than Go.
- TM can have anywhere from 2 to 5 players, although it is often played with exactly 4. For programming AI, the leap from 2 players to more than 2 is actually a lot more difficult than most people realize. You may have noticed that whenever you hear about an AI reaching superhuman performance, it’s almost always in a 2-player game.
- While a spot on a Go board can only have 3 states (white stone, black stone, or empty), a hex on a TM map can have 55 different states, taking into account the different terrain types and buildings. Add things in like towns and bridges and the complexity goes up from there.
- TM has 20 different factions using the Fire & Ice expansion, and each one of these factions has different special abilities and plays differently.
- TM has numerous elements that occur off the map including the resources and economies of each player, positioning on the cult tracks, and shared power actions.
- Each game is different by adding scoring elements and bonus scrolls that are different with each game. Which elements are present in the particular game can have a massive effect on all of the player’s strategies. Not to diminish the complexity of Go (a game which I’m still in awe of after casually studying it for over a decade), but you’re always playing the same game.
One of the things that makes TM such a great game and causes it to have a very high skill ceiling is the fact that its economies and player interactions are so tightly interwoven. The correct action to take on the map can be highly dependent on not only your own situation, but the economic states of your opponents or the selection of available power actions. All of this makes TM orders of magnitude more complex of a game than Go.
 Chaos Magicians, Swarmlings, Darklings, and Dwarves fight it out on the digital version of Terra Mystica. Complexities abound and an AI needs to know how to read the board. Darklings will want to upgrade one of their dwellings to get the town bonus. They should upgrade next to the Dwarves to keep power away from the stronger CM player. The choice of towns could affect the flow of the rest of the game:
Chaos Magicians, Swarmlings, Darklings, and Dwarves fight it out on the digital version of Terra Mystica. Complexities abound and an AI needs to know how to read the board. Darklings will want to upgrade one of their dwellings to get the town bonus. They should upgrade next to the Dwarves to keep power away from the stronger CM player. The choice of towns could affect the flow of the rest of the game:
- Should they take 7VP & 2 workers so they have enough workers to build a temple and grab a critical favor tile?
- Or 9VP & 1 priest that they can use to terraform a hex or send to the cults?
- Or 8VP & free cult advancements which will gain them power and cult positioning?
- 5VP & 6 coins is sometimes good, but probably not in this situation since the Darklings have other income sources.
The other town choices seem inferior at this point, which the AI needs to recognize. Notice what is needed to plan a good turn – the recognition that a town needs to be created this turn, the optimal location of the upgraded building, the knowledge that a critical favor tile exists and how to get it, the relative value of terraforming compared to other actions, the value of cult positioning (not shown) & power, as well as the value of coins which depend on how many coin-producing bonus scrolls are in the game.
The main idea behind training the network to become stronger is called bootstrapping. I’m simplifying things a bit here, but think of the neural network as an enormously complicated evaluation function. You feed it all the information about the map, the resources of all the 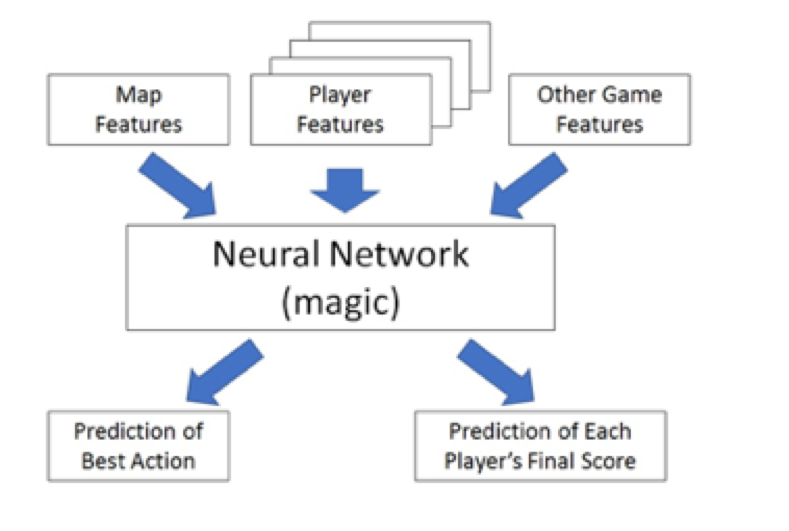 players, and other variables that describe the current game state. It crunches the numbers and spits out an estimate of the best action to take (each action is given as a percent chance that it is the best action) and an estimate of the final scores for each player. Let’s say you have a partially trained network that has an okay evaluation function, but not that good. You now use that, and each time you’re going to make a move you think 2 moves ahead, considering all the options and picking what you think is best. You’ll now have a (moderately) more informed estimate of your current state because you’ve searched 2 moves ahead. You now try to tweak that model so that your initial estimate is more similar to your 2-moves-ahead estimate. If you were able to fully incorporate everything from 2 moves ahead into your evaluation function, when you use this function to search 2 moves ahead, it’s equivalent to searching 4 moves ahead with your original function. It’s not that simple, but you can see how repeating this over and over again will keep improving the model as long as it has enough features to handle the complexity. You just have to repeat it billions of times…
players, and other variables that describe the current game state. It crunches the numbers and spits out an estimate of the best action to take (each action is given as a percent chance that it is the best action) and an estimate of the final scores for each player. Let’s say you have a partially trained network that has an okay evaluation function, but not that good. You now use that, and each time you’re going to make a move you think 2 moves ahead, considering all the options and picking what you think is best. You’ll now have a (moderately) more informed estimate of your current state because you’ve searched 2 moves ahead. You now try to tweak that model so that your initial estimate is more similar to your 2-moves-ahead estimate. If you were able to fully incorporate everything from 2 moves ahead into your evaluation function, when you use this function to search 2 moves ahead, it’s equivalent to searching 4 moves ahead with your original function. It’s not that simple, but you can see how repeating this over and over again will keep improving the model as long as it has enough features to handle the complexity. You just have to repeat it billions of times…
In order to train its networks, DeepMind was able to utilize a massive amount of hardware. According to an Inc.com article, the hardware used to develop AlphaZero would cost about $25 million. There is no way that a small company like ours would be able to compete with that. Some people have estimated that if you were to try and replicate the training done on a single machine, it would take 1,700 years! Even after all the training, when AlphaGo is run on a single machine, it still uses very sophisticated hardware, running dozens of processing threads simultaneously. We needed to create an AI that was capable of running on your phone. For each single position that AlphaGo analyzes, its neural network needs to do almost 20 billion operations. We were hoping to have a network with less than 20 million. And instead of analyzing 80,000 positions per second, we would be lucky if we could do 10. We also considered an even smaller network that could look at more positions per second, but it would not have enough complexity to incorporate a lot of the nuances needed for a strong player.
So our goal was to create an AI for a game that was even more complicated than Go, using a network about a thousandth the size. AlphaZero was able to play over 20 million self-play games in order to help its development. Even renting several virtual machines and playing games 24/7 for a few months, Digidiced was only able to collect about 40,000 self-play games. Despite these limitations, we were cautiously optimistic. We didn’t need super-human and god-like play. We wanted something that could be a challenge to the entire player base while not taking too long to think for each move.
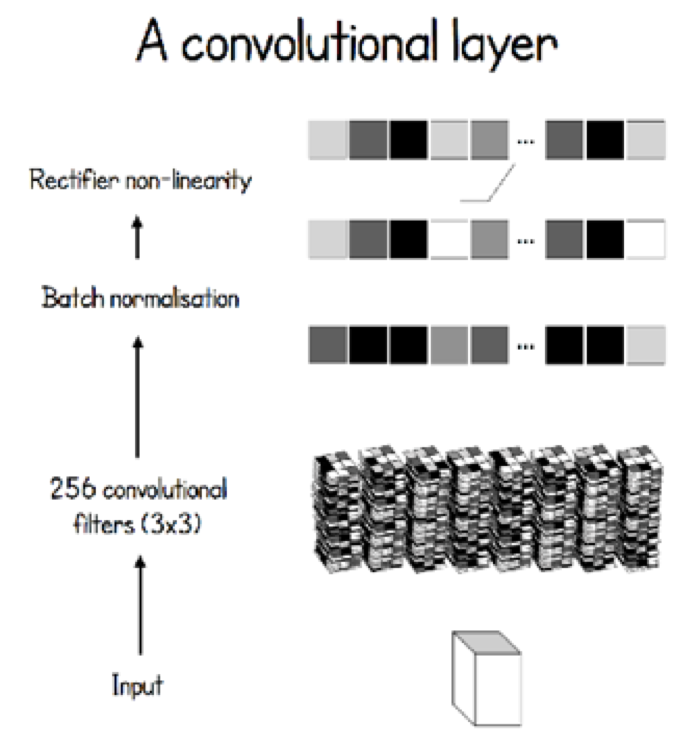 A tiny peek into the complexity of Alpha Go (from David Foster’s AlphaGo Zero Cheat Sheet).
A tiny peek into the complexity of Alpha Go (from David Foster’s AlphaGo Zero Cheat Sheet).
But even that turned out to be too much of a challenge with our limited budget. The AlphaZero paper claimed that starting from scratch and completely random play yielded better results than mimicking games played by humans. We decided to try both methods in parallel: one network would start from random play and build up network sophistication over time while another network was trained on games played on the app. Neither was able to create a very strong player; in fact, we were never able to create a version that could outperform our Easy version that used fairly standard Monte Carlo Tree Search. We even tried focusing the development on only 4-player games, but this didn’t help much.
What was really heartbreaking was that we could see the improvement that the network was making. We could see the improvement over time. But the rate of improvement was just too slow for the amount of money we were spending. It was a very difficult decision, but we’ve decided that we’re going to halt development work on this for now. We still see a possibility of spending some time converting the played games from Juho Snellman’s online implementation of TM, but we don’t have the funds for that now. Juho had very kindly given us permission to do that much earlier, but the conversion proved to be very difficult for a number of reasons, mostly due to how the platforms differed in accepting power. So while there is still a chance of further development, we don’t want to promise anything that doesn’t seem likely.
TM is too complex to use machine learning, the inputs&variables are too much, and the elements are too closely dependent.
It really is a bold move to try implementing AI this way. Appreciation.
I just wonder how other digital board games(such as Catan, Carcassonne,) made their difficult AI.
OpenAI Five proves you wrong. The only limiting factor here is resources, it costs to much to develop/run such networks.
The AIs in the Carcassonne app are not that strong. I regularly play the game with only the strong AIs and they make a couple of really stupid and unnecessary moves and so far I have beaten them continuously with a great gap in points.
That was a really interesting read. Thanks.
How is AI made for a game like Street Fighter? Or Civilization? Even Civilization 1 had challenging AI.
What makes TM more difficult than these examples?
Civilization 1 (and the newer games in the series) gave the AI a ridiculous starting advantage in resources. The computer players don’t even need to play by the same rules as the players! Street Fighter is a fast paced game with a lot of timing – the computer can have a perfect reaction time to pretty much anything. In a deterministic board game, it is much different as everyone has full access to all information and there is no way to cheat.
I think with more computing resources and more investment they could put together a stronger TM AI, but it probably wouldn’t be trivial.
I really enjoined the read. I am a PhD design candidate studying how to design for AI that can assist in design and would love to have a chat on the subject if you are interested.
Fascinating!!
What about the keldonai. A person made an ai better than most players for race for the galaxy.
I really love the game and all digidiced reproductions. Like agricola and le havre, i found them easy to beat after a while so i through in my own variables, like a handicap to make it more challenging.
Great article! One of the more interesting things I’ve read lately. Thanks!
You should hire Keldon Jones and not a guy with ‘some experience’
I’ll enjoy competing with Terra Mystica AI, both excited and apprehensive about these giant leaps in machine learning, despite Elon Musk’s warning…It’s all fun and games until “I have no mouth and I must scream”…
This reading was very interesting. Thank you!
Anyway, if the goal is to give a stronger AI, we don’t you simply enable handicap or, equivalently, configurable additional starting resources for AI? I know this is not the intent of this link, but for sure for you is way cheaper.
When you say you bootstrapped from games played by the app, do you mean by recording games played by human players or by the existing MCTS AI?
Would there be a benefit in the original AlphaGo style where the neural network was
My reaction is 2 years later and in the meanwhile, google has also done Starcraft 2 with AlphaStar. As I understand it, it works by observing human games and then playing games with itself. The board of Starcraft is considerably larger than terra mystica, and there are also way more building types. Also, evaluating the model (in non learning phase) needs to be quick as Starcraft is not a turn based game.
So I wondered, did you follow this and do you think (apart from the question if your company has the budget) that the alphastar way of ML could be applied to terra mystica?
Does the app really need a Hard version of the AI?
I can’t even beat Sir Losealittleless, supposedly the easiest AI level.